#. intro
This is a summary for the book, System Design Interview.
I am only writing this to not forget and read it whenever I need to remind myself.
1. SCALE FROM ZERO TO MILLIONS OF USERS
What databases to use
- structured Data: RDBMS(SQL) (join is easier/cheaper)
- Non-structured Data: None-RDBMS(noSQL)
- low latency - faster to retreive
- easy to scale out (add servers) - however RDBMS could also use sharding
- Sharding: separating DB into several servers
- Celebrity problem: one of servers could hit too often
- Join and de-normalization: when it’s too separated, join cost could be big.
load balancing
- Pro:
- Can handle big amount of traffic
- better security - only load balancer can reach the server
Database replication
- Master - Slaves : write to master and read from one of slaves. Master’s data will be copied to slaves.
- Master offline -> one of slaves became the master
- Consistence hashing for reading slaves?
- Write would have big traffic …
Cache
- things to think about:
- consistency
- Expiration policy
- Eviction policy : what to delete when it’s full
- Single point of failure : when cache server is down, all the traffic would go to the server -> maybe recommended to use
rate limiter
CDN ★
- Geographical server. Content delivery network. Storing static datas(Images, videos, CSS, JS files ..)
- It will reduce the latency by big time locally.
Stateless vs Stateful
- Stateless(JWT, session) all the way :
- scalability
- robustness(HA)
- For stateless: Message queue can be used for the communication.
2. BACK-OF-THE-ENVELOPE ESTIMATION
things to think about first
- read count per sec : QPS(query per sec)
- peak QPS : 2 * QPS
- write count per sec
- data type/size per request : storage requirement
- daily active user?
- cache?
- number of servers????
3. Interview process
- Understand requirement and establish design scope limit
- What is the most important function of the system?
- QPS, writes per sec, which storage, storage size, cache, server side render/client side render
-
Propose high level design and be pursuasive
-
Design and deep dive
- wrap up
things to remember
- Always ask for clarification
- Possibly suggest multiple approaches
- Mind the time, so don’t go too deep unless it’s neccesary
4. Rate Limiter (CODE: 429)
Rate Limiter is to limit the request per IP (somesort).
- prevent D-DoS (distributed denial of service)
Where?
- can be located in-between any layers: but generally client <-> API server
How? (algorithm)
Token bucketLeaking bucket- Fixed window counter: certain coounters per fixed timeline
- Sliding window log: FIFO - sliding time frame with log data
- ⭐Sliding window counter
- use headers: X-Ratelimit-Remaining/Limit/Retry-After
Problems in a distributed system
- Race condition: write-read consistency :: lock
- Lua script/sorted set data
- synchronization issue in different servers:
- using centralized data stores such as Redis
Performance Optimization
- multi-data center setup is crucial
- eventual consistency model: consistency guranteed after N time
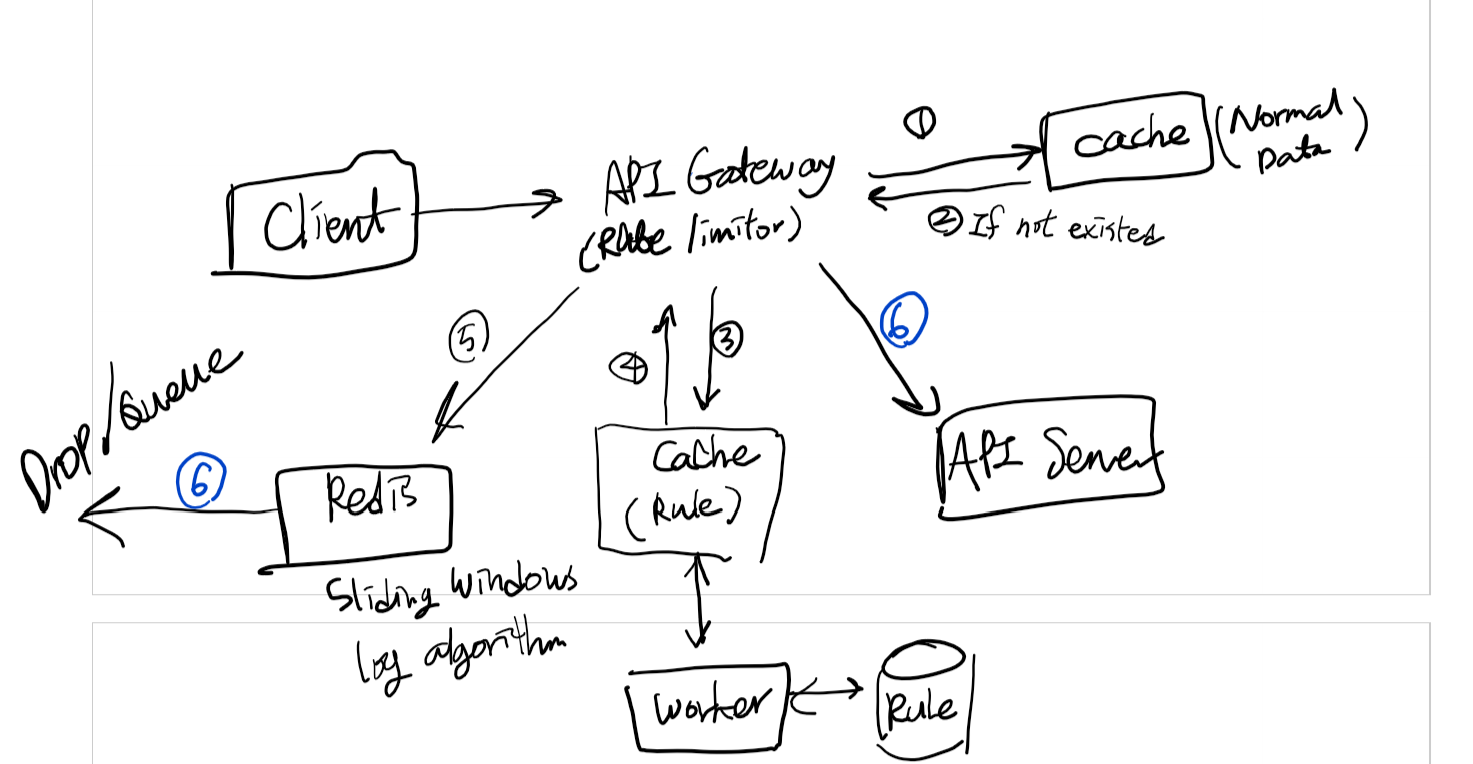
- if the data is stored in cache, it won’t go through rate limiter.
5. CONSISTENT HASHING
Important concept for traffic distribution, especially when scale out. Could be applied to Load balancer, also sharded DB
- hashvalue? [0-9a-zA-Z] : 62 possible chracter per block.
Hash ring:
- with more virtual servers/nodes, distribution is almost even.
- When 1 server down, only k/n hash keyes need to be re-allocated. (k = # of hash key, n = # of server/node)
6. DESIGNING A KEY-VALUE STORE
This example is about a key-value storage with consistent hashing using a hash ring.
CAP theorem
It is impossible for a distributed system to simultaneously provide more than two out of the following three guarantees: consistency, availability, and partition tolerance.
- Consistency: all nodes see the same data at the same time
- Availability: every request receives a response - no failures or timeouts
- Partition tolerance: system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
Since nextwork failure is unavoidable, Partition tolerance is a must.
Data partitioning
- consistent hashing could be used for data partitioning.
- It has following advantages:
- Auto-scaling
- Heterogeneity: You can have multiple virtual nodes which would enable to have more even distribution.
Data replication
You normally replicate data to multiple nodes to prevent data loss.
This can be performed to clockwisely the most closed N nodes - becuase it has higher chance that those closest nodes are not virtually assigned to the same server.
Nodes in the same data center are more likely to fail at the same time. For better reliablity, you should distribute replicas across different data centers.
Consistency
When you read or write data, you need to do it with multiple different nodes to check consistency.
- N: # of replicas
- W: # of replicas to write
- R: # of replicas to read
If W + R > N, strong consistency is guaranteed. (Usually N = 3, W = R = 2)
If R = 1 && W == N, the system is optimized for a fast read. (Because it will fix data as writing)
If W = 1 && R == N, the system is optimized for a fast write. (Because it will fix data as reading)
If W + R <= N, strong consistency is not guaranteed.
Incinsistency resolution & handling
- Vector clock is well known concept to detect inconsistency.
- Gossip protocol is a better way to detect inconsistency.
When resolving inconsistency, you can use last write wins or last read wins.
7. DESIGN A UNIQUE ID GENERATOR IN DISTRIBUTED SYSTEM
Possible solution would be:
- UUID
- Ticket server: Single point of failure
- Twitter snowflake: 64bit long: Can be sorted by time
- 1bit: sign
- 41bit: timestamp
- 5bit: datacenter id
- 5bit: machine id
- 12bit: sequence number
Although UUID would solve the problem, using snowflake would be better because it contains meaningful data in ID, such as time, datacenter, machine.
8. DESIGN A URL SHORTENER
Things to consider:
- 301 redirect vs 302 redirect
- 301: permanent redirect -> client will cache the redirect
- It won’t go through the server: faster
- 302: temporary redirect -> client will not cache the redirect
- It will go through the server: slower
- For analytics, it makes sense to use 302 because it will go through the server all the time.
- Hash value:
- Depends on how much data you want to store, you can use N digits of hash value. One digit can represent 62 values [0-9a-zA-Z]. So for example, if you need to store more than 55 billion data, you can use 6 digits of hash value. (62^6 = 56,800,235,584)
- Hash collision:
- You have to check weather the new hash value is already used. If it is, you have to generate a new hash value. For this performance, bloom filter is a good solution.
So, the overall process for client would be:
- A user clicks a shortened URL
- The load balancer forward the request to the web server
- If the URL is in the cache, return that
- If not, check the database. If it is not in the database, return 404
- Redirect the user to the original URL
Overall process when creating a new shortened URL:
const hashValue = generateHashValue(originalURL);
while(hashValue is already used) {
hashValue = generateHashValue(originalURL);
}
store hashValue and originalURL in the database